前几天谈了正则匹配 js 字符串的问题:《》 和 《》。
里面讲到了优化正则起到提升性能的问题,但是能提升多少呢?于是我去测试了,发现TMD几乎微乎其微,我用1千字符串进行100万次匹配测试,优不优化根本没区别。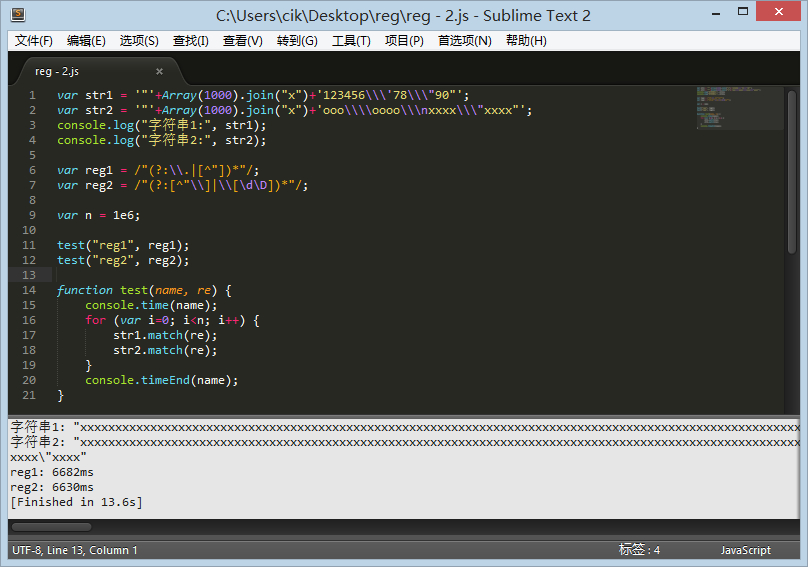
这不科学,我白看了这么多天正则,上天这是在玩弄我么。
突然我想到了 compile 方法,然后去测试了下,奇迹出现了,果然优化过的快了不少。
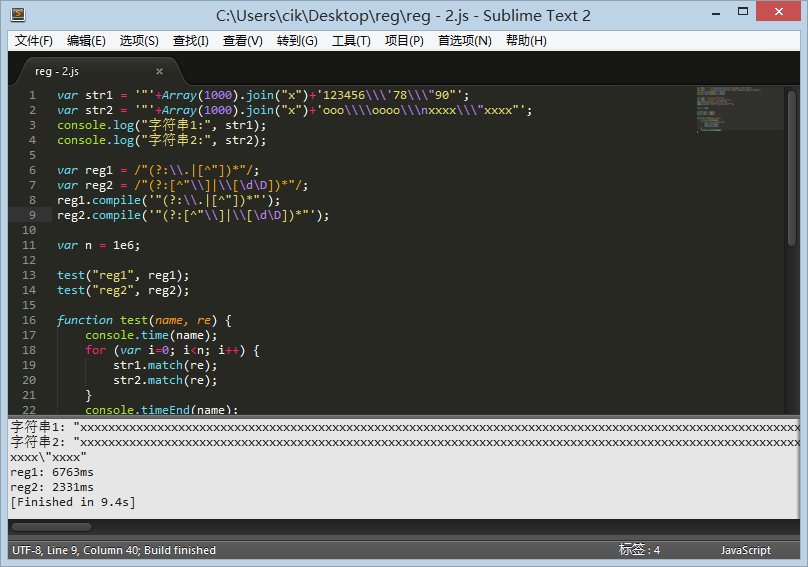
但这是为什么呢?
于是我翻阅资料,在 MDN 上找到了 这里说 compile 方法已被弃用!这不科学。。。在 stackoverflow 上发现这篇文章 文章大意是说其实 直接 new RegExp 即可,compile 几乎用不到。于是乎我修改了代码再来一次。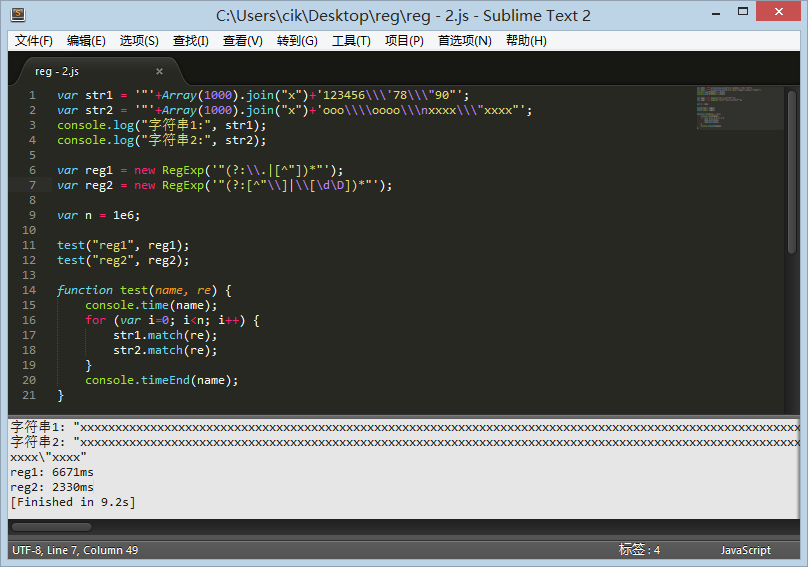
果然,直接 new RegExp 效果和 compile 是一样的。
不过这只是 nodejs 下的结果,我们去看看各个浏览器下的结果如何吧。test
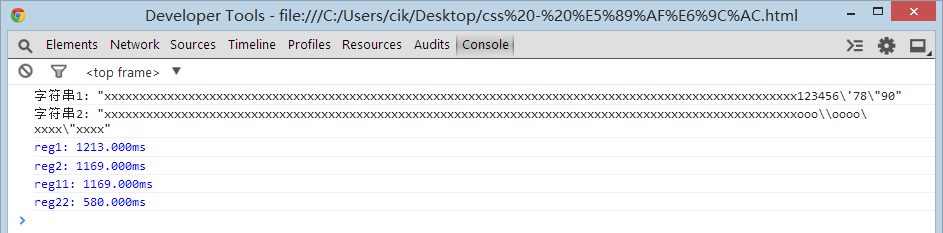 chrome
chrome
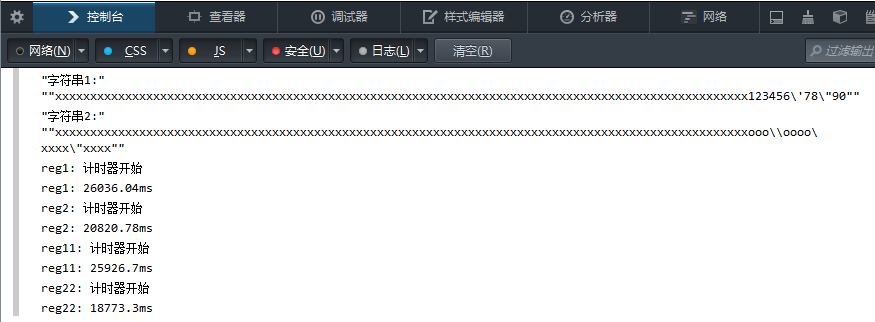
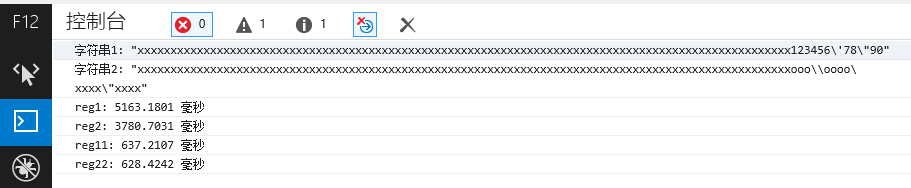
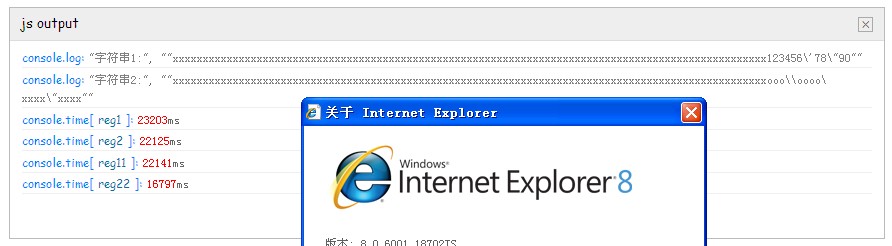
很明显,第一名是 chrome (以 reg22 那个优化过的为准),这个号称武装到牙齿的货,果然够new逼。
不过 firefox 这货,竟然连 IE8 都比不过,是不是太怂了点。优化过的 正则 比没优化的快,那是肯定的。
但是 正则字面量 和 new RegExp 比,那就不是一个档次了。为什么有如此大的差距呢?其实我也没搞清楚。以前看到很多文章都说 字面量 会比 new 对象 形式效率高,但是在正则这里,好像不是这么回事。
不过也不能直接否认这个观点,因为我一直都用字面量的,简洁美观,用着方便才是王道。我觉得在数据量大,或者重复操作次数多的时候用 new RegExp 是很必要的。
因为你也看到了性能提升这么多。当然前提条件是你的正则必须优化,正则没优化的情况,两种差不多。所以优化你的正则,然后用 new RegExp 可以大幅度提升程序的性能。PS: IE11 是个特例,这货从来不安套路出牌。
好了今天的分享完毕,你们都蠢蠢欲动了吧,快去把正则各种new起来吧。
